pythonで時系列データを扱うには、pandasを使います。pd.read()でCSVファイルを読み込みますが、
- 時系列分析であることを示すこと
- csvファイルで読み込んだ日付の列をインデックスにすること
を示すことが必要です。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

【python】pythonのまとめ
経済統計の使い方では、統計データの入手法から分析法まで解説しています。
https://officekaisuiyoku.com...
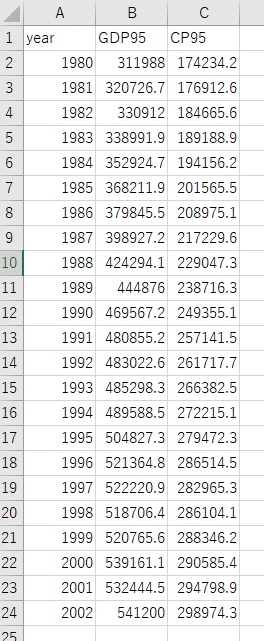
pythonで時系列データの扱う方法を説明します。パッケージはpandasを使います。以下のCSVファイルをデータとして使います。
通常のデータフレームでは、行番号を示すインデックスは、ゼロから順に番号が振られますが、インデックスを日付に変えて、時系列データとして使います。そのためには、
- 時系列分析であることを示すこと
- csvファイルで読み込んだ日付の列をインデックスにすること
が必要になります。
import pandas as pd
cp=pd.read_csv("cp.csv",parse_dates=True,index_col='year')parse_dates=True で時系列分析にできます。
index_col=’year’ で’year’の列をインデックスとして使うことを指定します。日付の書式のデフォルトは「yyyy-mm-dd」です。csvファイルは年のデータなので、1980など4桁だけいれてあります。
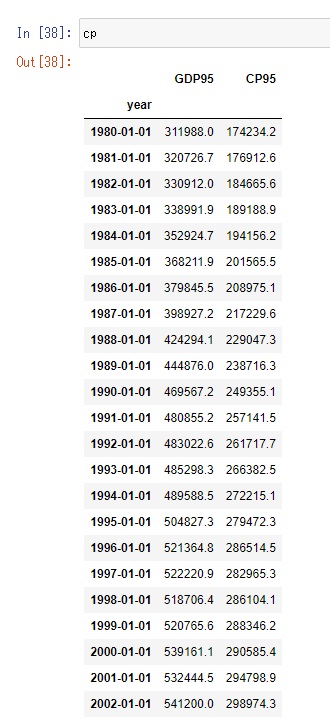
これを実行すると以下のようにデータが読み込まれます。yearの列が日付データとなっています。
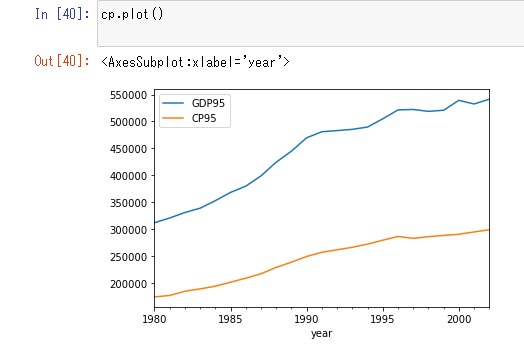
cp.plot()でグラフで書くと以下のようになります。
エクセルばかり使ってたので、2022/04/05のような書式がデフォルトなのかと思っていましたが、2002-04-05の書式がデフォルトでした。
1980と入力しても1980-01-01に変換してくれます。
スポンサーリンク
スポンサーリンク