ここでは、pythonを使った決定木の分析を説明します。機械学習に分類されますが、手法自体は古くからあり、解釈がしやすいのが特徴です。
決定木の分析をする前に、データをあらかじめ加工しておく必要があります。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

カテゴリー変数の数値化
カテゴリー変数とは、「良い」「悪い」とか、「A型」、「B型」、「AB型」、「O型」など、いくつかのカテゴリー(種類)に分けられるデータです。
これを計算に使うには0や1などに数値化する必要があり、それをエンコーディングと呼びます。
scikit-learnのproprocessingモジュールのLabelEncoderを使います。
le.transform()で数値に変換します。そのままだとarrayになるので、pandasのSeriesの形にするため、pd.Series()を使います。fit()は、データに基づいて変換のためのパラメータを学習します。transform()は 学習したパラメータを用いてデータを変換します。
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
le.fit(y)
y=pd.Series(le.transform(y))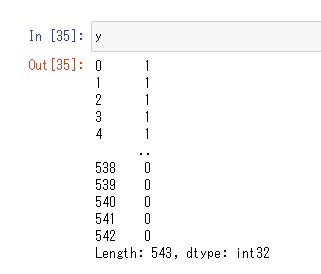
データの正規化
データの大きさをそろえるために、正規化します。ここでは、最小最大正規化を行いました。データの最大値と最小値を使って、最小値が0、最大値が1となるようにします。
$ x’= \frac{x-最小値}{ 最大値-最小値 } $
scikit-learnのproprocessingモジュールのMinMaxScalerを使います。fitとtransformを使うのはLabelEncoderと同じです。
from sklearn.preprocessing import MinMaxScaler
mmsc=MinMaxScaler()
mmsc.fit(X)
X=pd.DataFrame(mmsc.transform(X))結果は以下のようになります。
X.columns=[“IIP”,”SeisanZai”,”TaikyuSyohizai”,”RoudouTounyuRyou”,”Toushizai”,”Kouri”,”Orosiuri”,”EigyoRieki”,”YuukouKyujin”,”Yusyutusuuryou”]
決定木の作成
決定木を作成します。データは、景気の状態を説明変数、景気動向指数の10個の指標を説明変数として、決定木による分析をしてみます。景気動向指数の各指数は、最大値と最小値を使って正規化しています。
DecisionTreeClassifierを使います。ここで使うモデルは、treeという名前です。枝の数は3としています。
from sklearn.tree import DecisionTreeClassifier
tree=DecisionTreeClassifier(max_depth=3)
tree.fit(X_train,y_train)決定木の描画
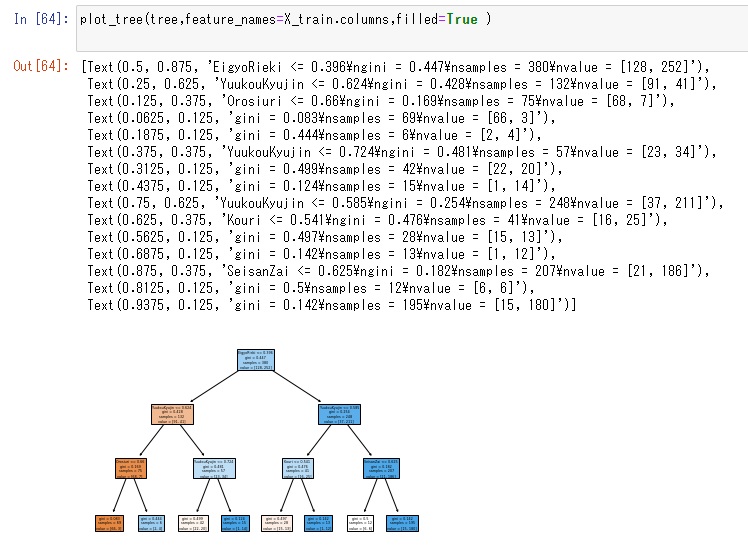
上のモデルを使って、木を描いてみます。plot_tree関数を使います。
from sklearn.tree import plot_tree
plot_tree(tree,feature_names=X_train.columns,filled=True )