gretlでパネルデータを読み込んで、推計し、検定するまでの流れを解説しました。
パネルデータは、時系列データとクロスセクションデータが両方あるデータです。
推計法としては、プーリングモデル、固定効果モデル、変量効果モデルがあります。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

データの読み込み
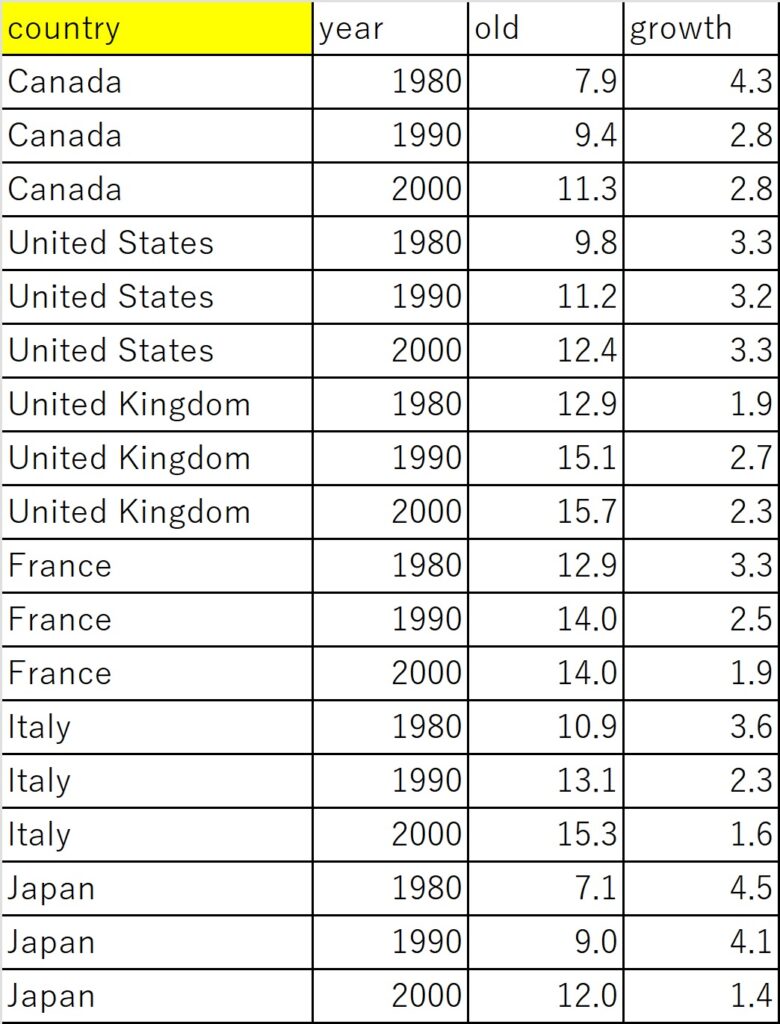
パネルデータを読み込む時は、個体(ユニット(グループ)・インデックス変数)と時間(タイム・インデックス変数)の変数の列を作っておきます。個体、時間の順に作っておくとよいでしょう。下の表の例では個体としてcountry、時間としてyearを作っています。oldは、65歳以上の人口比率、growthは10年間の年間平均成長率です。
gretlで読み込みます。「ファイル」→「ファイルを開く」→「ユーザー・ファイル」とします。
ファイルの種類を「Excelファイル(*.xlsx)」にした後、データのエクセルファイルを選びます。
シートが複数ある場合は、シートも選びます。メッセージが出るので「閉じる」を押した後、以下のボックスが出てきます。
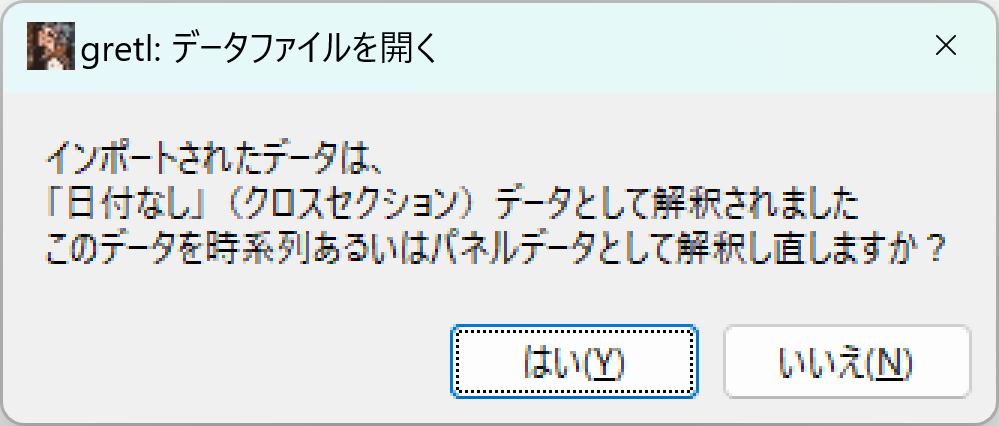
「このデータを時系列あるいはパネルデータとして解釈し直しますか?」と聞いてくるので、「はい」を押します。
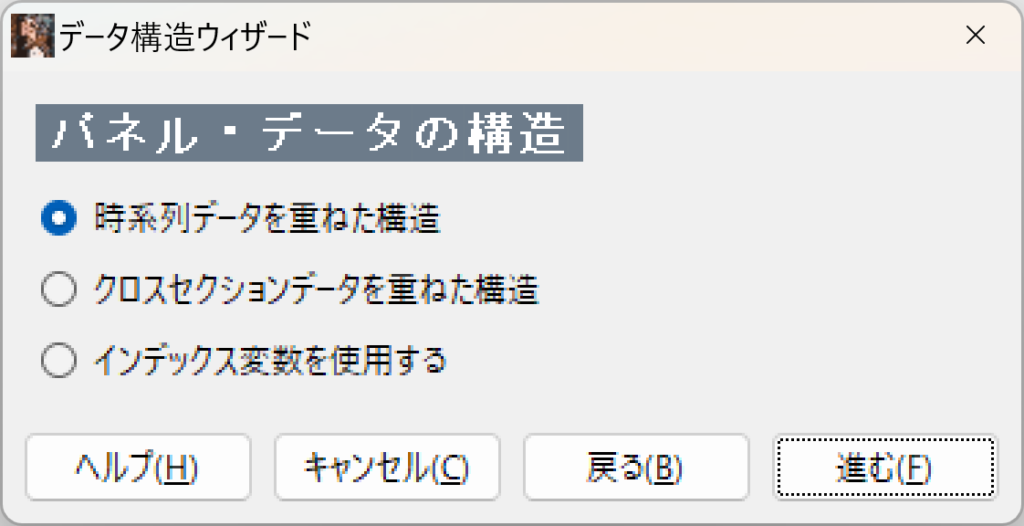
パネルデータの構造を聞いてきます。「インデックス変数を使用する」を選びます。
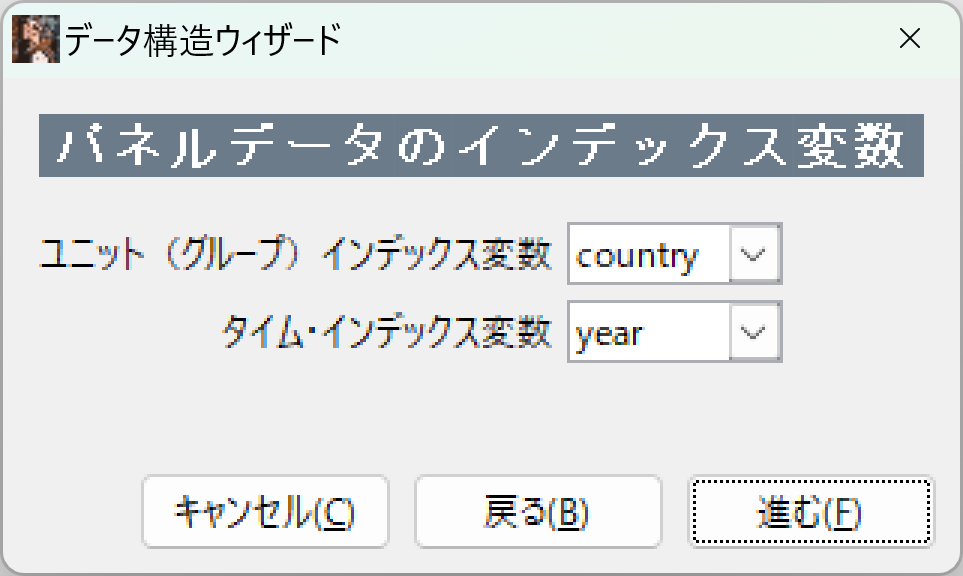
インデックス変数を、ユニット(グループ)インデックス変数、タイム・インデックス変数の順に作っておくと、変更せずにすみます。
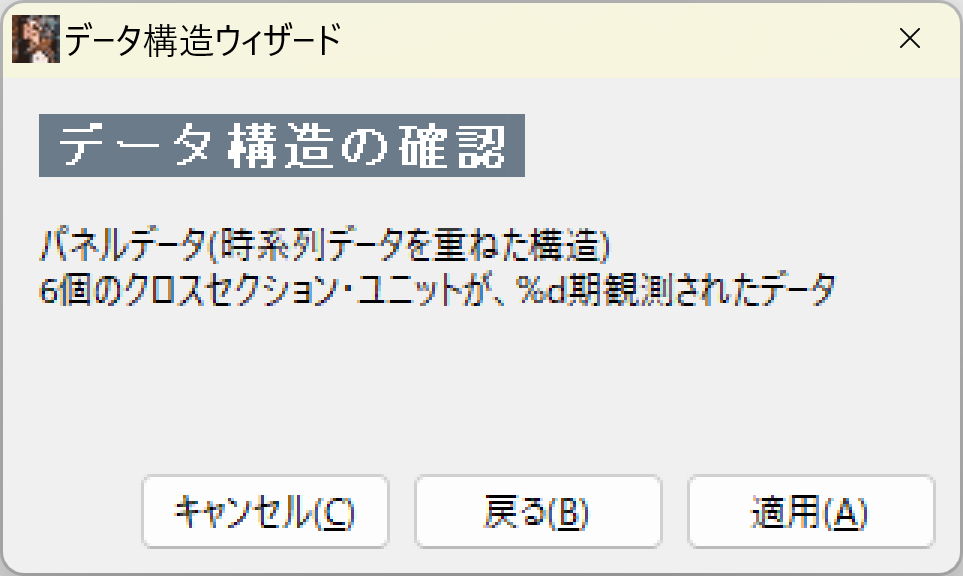
進むを押すと、「6個のクロスセクション・ユニットが%d期観測されたデータ」と出てきますので、「適用」を押すと、データがインポートされます。
推定
パネルデータの推定をします。高齢化比率(65歳以上人口の人口全体に占める比率)がその後10年間の平均実質経済成長率にどのような影響を与えるかを調べています。
$ その後10年間の平均実質経済成長率=\alpha+\beta ×65歳以上の人口比率 \text{+} 個別効果 \text{+} 残差 $
「モデル」→「パネル」→「固定効果あるいは変量効果」を選びます。
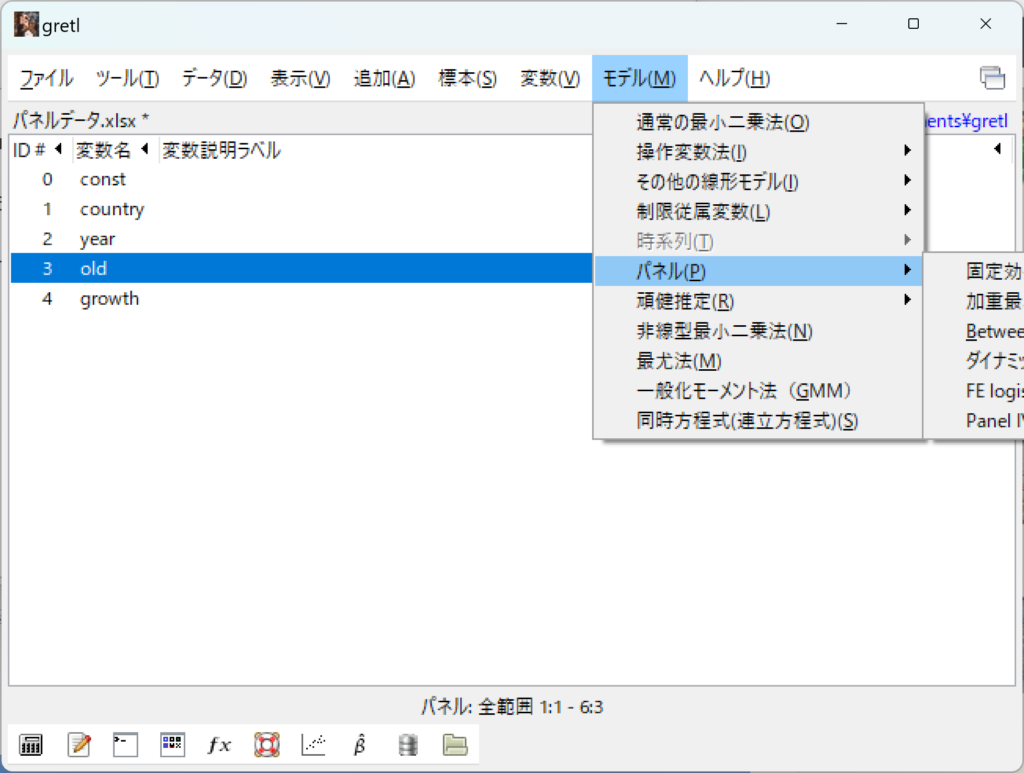
固定効果と変量効果の違いなどは以下の記事を参考にして下さい。
- プーリングモデル 個別の効果を考慮しない
- 固定効果モデル 個別の効果が説明変数と相関している場合
- 変量効果モデル 個別の効果が説明変数と相関していない場合
固定効果
固定効果で推計する場合は、左下のボタンを「固定効果」のままにして、被説明変数にgrowth、説明変数にoldを選びます。
推計結果が出力されます。
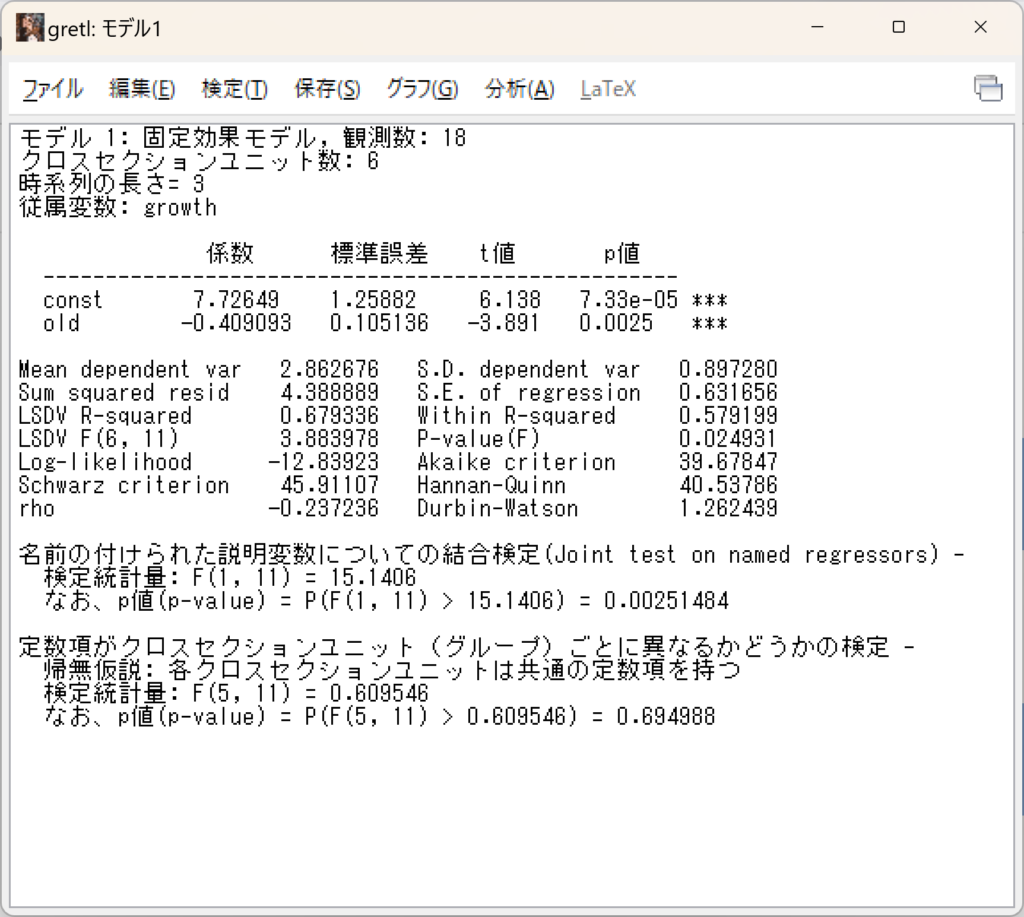
係数は、-0.41と推計されました。
帰無仮説「各クロスセクションユニットは共通の定数項を持つ(プーリングモデルである)」かどうかの検定(F検定)では、p値が0.69なので、5%水準で帰無仮説が棄却できません。この場合は、国ごとに共通の定数項を持つことが支持されます。プーリングモデルでよいということです。
変量効果
変量効果で推計する場合は、推計メニューで「変量効果(ランダム効果)」を選びます。
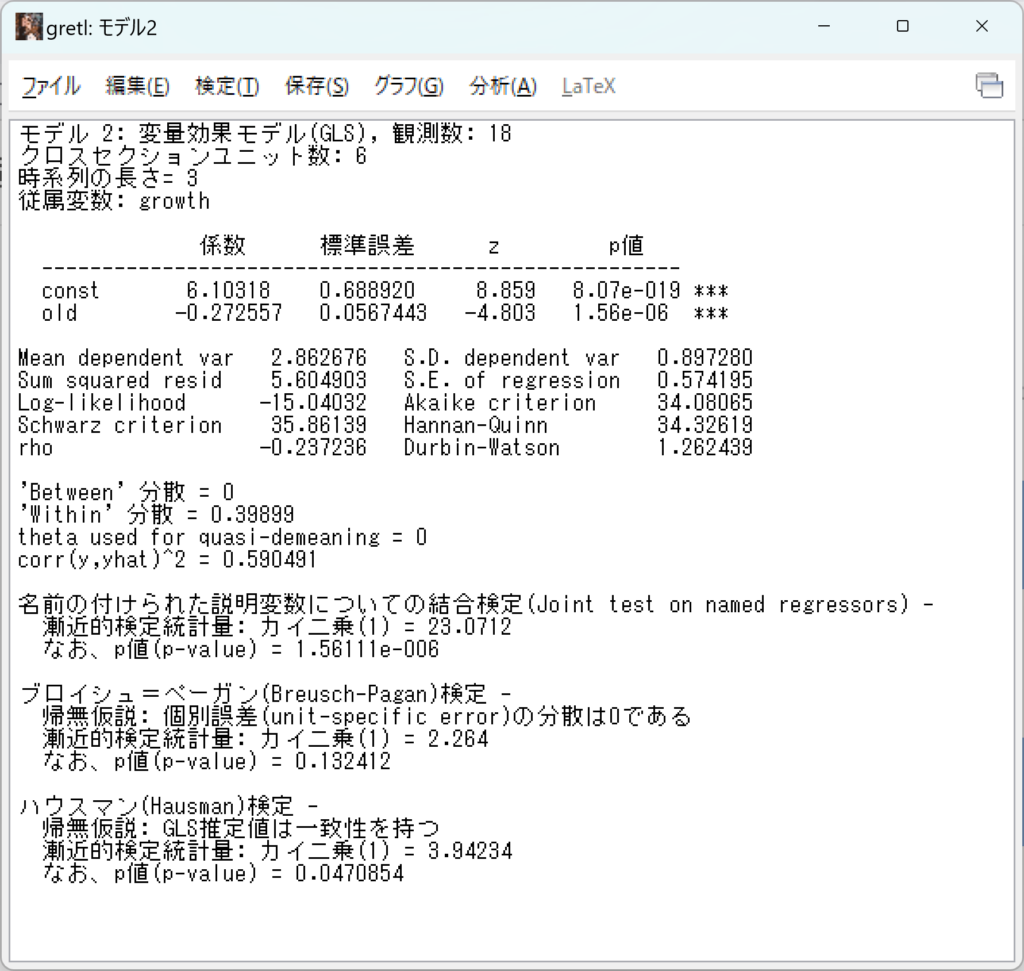
変量効果の場合、係数が-0.27です。
ブロイシュ=ペーガン検定は、帰無仮説が「個別誤差の分散はゼロ(プーリングモデルである)」の検定です。プーリングモデルか変量効果モデルを選択する検定です。p値は、0.13なので、5%水準で帰無仮説は受容されます。つまり、プーリングモデルであることが支持されます。
ハウスマン検定は、帰無仮説「GLS推定値は一致性を持つ(変量効果モデルである)」の検定で、固定効果モデルか変量効果モデルかを選ぶ検定です。p値は0.047で5%水準では棄却されます。この結果からは、固定効果モデルが支持されます。
以下をまとめると以下の結果です。
- F検定 固定効果モデル VS プーリングモデル → プーリングモデル
- ブロイシュ=ペーガン検定 変量効果モデル VS プーリングモデル → プーリングモデル
- ハウスマン検定 固定効果モデル VS 変量効果モデル → 固定効果モデル
プーリングモデルで推計するのが良いという結果になりました。
まとめ
- エクセルからデータを読み込むときは、個体変数と時間変数を作っておく
- 固定効果の結果には、個別効果の有無に関するF検定も出力される
- 変量効果の結果には、プーリングモデルと変量効果の検定であるブロイシュ=ペーガン検定と固定効果と変量効果の検定であるハウスマン検定が出力される。