csvファイルなどからデータを取り入れた後、データの一部を抽出したい場合があります。python上に、データフレームとしてデータがあることを前提に、行番号や列番号を指定してデータの抽出する方法を説明します。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

データフレームの一部を指定
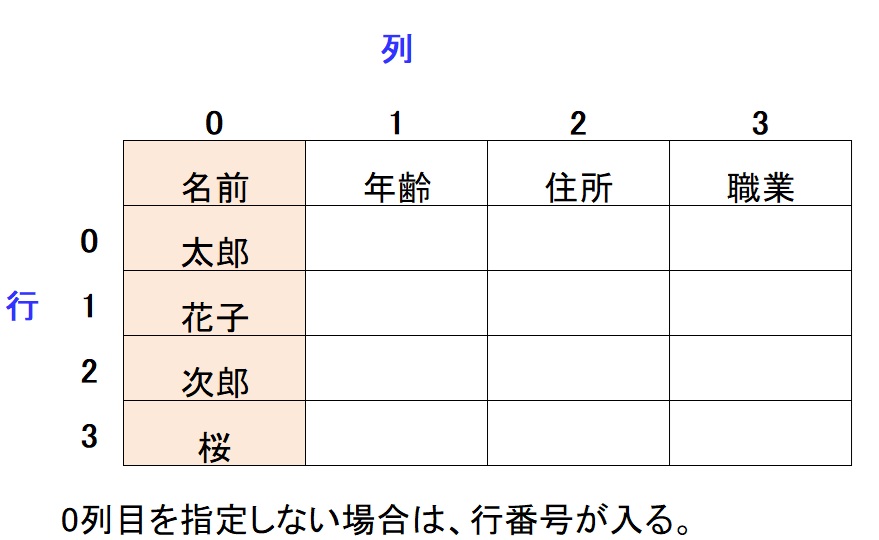
データフレームは、変数名が最初の行にあり、列ごとにデータが格納されています。
データフレームでは、通常、最初の行(インデックス0)からデータが始まり、列名は別途定義されます。CSVファイルを読み込む際、header=0を指定すると、最初の行が列名として扱われます。列は、0列目がインデックス列で、名前を指定しない場合は、行番号(0,1,2,3…)が入っています。
データフレームに対して行と列を指定すればデータが抽出できますが、locメソッド、ilocメソッドの2つの方法があります。
locメソッド
locメソッドは、行や列の「ラベル」を指定してデータを抽出する方法です。ラベルが文字列の場合は、クォーテーション(’)で囲みます。locはlocationの略です。ラベルは通常文字列です。locメソッドは、行や列のラベルを指定してデータを抽出します。データフレームに明示的なラベルが設定されていない場合、デフォルトで0から始まる整数のインデックスが使用されます。
新データフレーム名=データフレーム名.loc[ ‘行の名前’, ‘列の名前’]
また、データフレームは行と列からできているので、行と列を指定するのが普通ですが、’列の名前’を省略して、行の名前だけを指定する(loc[‘行の名前’])と、行のデータが抽出されます。
ilocメソッド
ilocメソッドは行番号や列番号を指定する方法です。index locationの略です。
行や列の名前を指定するlocメソッドは、プログラムとしてはわかりやすいですが、実際に使うとなると文字列の入力が面倒な場合があります。ilocメソッドはすべて数字で指定します。
抽出して新たなデータフレームを作る場合は、以下のように指定します。
新データフレーム名=データフレーム名.iloc[ 行番号指定 , 列番号指定]
行番号や列番号の指定
行や列を一つだけ選ぶ場合は、行番号や列番号を指定すればよいです。行番号や列番号は0から始まっているところに注意が必要です。連続しない複数の行や列を選ぶ場合は、カッコ[]で括ったうえで、カンマで区切って指定すればよいです。[0,[1,2]]といった形になります。
スライス記法
スライス記法は、:を使って、行や列をスライスして取り出す方法です。要素が0,1,2,3,4,5の時、この記法によって何が取り出せるかをまとめます。ilocメソッドではa:bの場合、a列からb列の一つ前までが対象となります。ilocメソッドでは終了ラベルは含まれません。一つ前までなので、注意して下さい。一方、locメソッドでは終了ラベルを含みます。df.iloc[0:5,0]は、0,1,2,3,4の行を抽出しますが、df.loc[0:5,0]は0,1,2,3,4,5の行を抽出します。
import pandas as pd
df1=pd.DataFrame({'x':[1,2,3,4,5]})
df2=df1.iloc[0:4,0] #ilocメソッド
df3=df1.loc[0:4,'x'] #locメソッド
print(df2)
print(df3)出力は以下です。
0 1
1 2
2 3
3 4
Name: x, dtype: int64
0 1
1 2
2 3
3 4
4 5
Name: x, dtype: int64import pandas as pdー1は終了ラベルを表す
マイナスをつけると、終了ラベルからの行数や列数を表します。‐1は終了ラベル(後ろから1番目)、‐2は後ろから2番目を表します。ilocメソッドでdf.iloc[0:-1,0]とすると、ゼロから、終了ラベル(-1)の一つ前を抽出します。-2とすると、ゼロから、終了ラベルから2つ前のデータ(-2)の一つ前までを抽出します。locメソッドではマイナスは使えません。
import pandas as pd
df1=pd.DataFrame({'x':[1,2,3,4,5]})
df2=df1.iloc[0:-1,0] #-1まで
df3=df1.iloc[0:-2,0] #-2まで
print(df2)
print(df3)出力は以下の通りです。
0 1
1 2
2 3
3 4
Name: x, dtype: int64
0 1
1 2
2 3
Name: x, dtype: int64:のみ
:のみだとすべての要素を表します。
import pandas as pd
df1=pd.DataFrame({'x':[1,2,3,4,5]})
df2=df1.iloc[:,0]
df3=df1.loc[:,'x']
print(df2)
print(df3)出力は以下の通りです。
0 1
1 2
2 3
3 4
4 5
Name: x, dtype: int64
0 1
1 2
2 3
3 4
4 5
Name: x, dtype: int64なぜ最終ラベルが含まれないのか
ilocメソッドではなぜ「一つ前まで」なのかですが、0~6行を0~3と4~5に分ける場合、[:4,:],[4:,:]と簡明な形で表せることが大きいのではないかと思います。
locメソッドで最終ラベルが含まれるのは、こちらは文字列ベースの取り扱いなので、通常の人間の感覚に合わせて最終ラベルも含まれるということだと思います。
| スライス記法 | 結果 |
| 1:3 | 1,2 |
| 2: | 2,3,4,5 |
| :3 | 0,1,2 |
| -1 | 5 |
| : | 0,1,2,3,4,5 |
例を一つ示しておきます。データフレームを作り、0~3行と4行~6行に分ける場合です。
import pandas as pd
df1=pd.DataFrame({'x':[1,2,3,4,5,6,7],'y':[2,3,4,5,6,7,8]})
print(df1)
df2=df1.iloc[:4,:]
df3=df1.iloc[4:,:]
print(df2)
print(df3)
出力は以下のようになります。
x y
0 1 2
1 2 3
2 3 4
3 4 5
4 5 6
5 6 7
6 7 8
x y
0 1 2
1 2 3
2 3 4
3 4 5
x y
4 5 6
5 6 7
6 7 8シリーズとして扱う:カラム名を指定
Pandasでは、データフレームから特定の列を抽出する際に、Seriesとして扱うの方法です。変数名(カラム名)’x’の列を抽出するには、df1[‘x’]と指定します。データフレームなのに、一つだけ変数を指定するという方法です。変数名(カラム名)を複数指定するときは、リストにします。df1[[‘x’,’y’]]という形です。
import pandas as pd
df1=pd.DataFrame({'x':[1,2,3,4,5]})
print(df1['x'])
出力結果は以下です。
0 1
1 2
2 3
3 4
4 5
Name: x, dtype: int64行の抽出:行のフィルタリング
また条件式を書くことによって特定の行を抽出することができます。条件式は、ある列に関したものを指定します。
df[df[‘x’]=’tokyo’]
import pandas as pd
df1=pd.DataFrame({'x':['Tokyo','Nagyo','Osaka','Fukuoka'],'y':[2,3,4,5]})
print(df1)
df2=df1[df1['x']=='Osaka']
print(df2)
出力
x y
0 Tokyo 2
1 Nagyo 3
2 Osaka 4
3 Fukuoka 5
x y
2 Osaka 4