データフレームの変数を抽出したり加工したりする方法を解説します。
データフレーム$列名が基本的な変数の取り出し方ですが、複数のデータを操作する場合は、列番号を指定する方が便利なことも多いです。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

【R】Rのまとめ
経済統計の使い方では、統計データの入手法から分析法まで解説しています。
https://officekaisuiyoku.com...
変数の抽出
以下のデータフレームを作ります。データフレーム名はtestとします。
| A | B | C | D | |
| 1 | 1 | 6 | 11 | 16 |
| 2 | 2 | 7 | 12 | 17 |
| 3 | 3 | 8 | 13 | 18 |
| 4 | 4 | 9 | 14 | 19 |
| 5 | 5 | 10 | 15 | 20 |
test<-data.frame("A"=c(1:5),"B"=c(6:10),"C"=c(11:15),"D"=c(16:20))または、
test<-data.frame(matrix(seq(1,20),5,4))
colnames (test) <- c("A","B","C","D")抽出の方法は何通りかありますが、それぞれの変数を操作するにはデータフレーム$列名が最も使いやすいです。複数の変数を処理するには列番号が便利です。
- データフレーム$列名
- データフレーム[[列番号]] リスト形式で指定
- データフレーム[,列番号] 行列形式で指定
- データフレーム[列番号] リストとして取り出す
それぞれの結果は以下のようになります。
> test$A
[1] 1 2 3 4 5
> test[[1]]
[1] 1 2 3 4 5
> test[,1]
[1] 1 2 3 4 5
> test[1]
A
1 1
2 2
3 3
4 4
5 51列目から3列目までを取り出す場合は、行列形式かリストで取り出すことでできます。
> test[,1:3]
A B C
1 1 6 11
2 2 7 12
3 3 8 13
4 4 9 14
5 5 10 15
> test[1:3]
A B C
1 1 6 11
2 2 7 12
3 3 8 13
4 4 9 14
5 5 10 15変数の加工
変数の加工は$マークを使えば簡単にできます。平均をとるにはmean関数を使います。すべての期に平均のデータが入ります。
下の例は、Aについて平均をとり、同じデータフレームにaverageAとして追加する場合です。
> test$averageA<-mean(test$A)
> test
A B C D E averageA
1 1 6 11 16 21 3
2 2 7 12 17 22 3
3 3 8 13 18 23 3
4 4 9 14 19 24 3
5 5 10 15 20 25 3データフレーム名を指定しないと、ベクトルとして保存されます。
> averageA<-mean(test$A)
> averageA
[1] 3
> str(averageA)
num 3よく使う関数としては以下のものがあります。
| 関数名 | 説明 |
| abs | 絶対値 |
| exp | 指数 |
| sqrt | 平方根 |
| log | 自然対数 |
| log10 | 常用対数 |
| diff | 要素間の差分 |
複数の変数に適用する統計量としては以下のものがあります。
| 関数名 | 説明 |
| sum | 合計 |
| mean | 平均 |
| median | 中央値 |
| var | 分散 |
| sd | 標準偏差 |
変数を一括して変換する
データフレームの変数を一括して変換する方法として、apply関数があります。
$ apply(データフレーム,1or 2,関数)$
2番目の引数には、行ごとに処理する場合は1,列ごとに処理する場合は2を入れます。変数を一括処理する場合は、2を選びます。
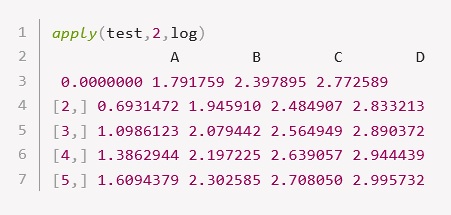
上記のtestデータについて、すべての変数を対数に変換するには、apply(test,2,log)で実行できます。
apply(test,2,log)
A B C D
[1,] 0.0000000 1.791759 2.397895 2.772589
[2,] 0.6931472 1.945910 2.484907 2.833213
[3,] 1.0986123 2.079442 2.564949 2.890372
[4,] 1.3862944 2.197225 2.639057 2.944439
[5,] 1.6094379 2.302585 2.708050 2.995732スポンサーリンク
スポンサーリンク