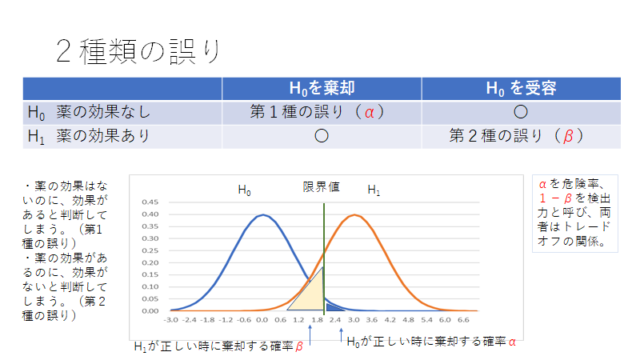
表の形式にはワイドデータとロングデータがあります。ワイドデータは行と列に属性や年などがあるもので、一般的にみられるデータです。ロングデータは、各行に一つのデータが入ったもので、コンピューターで計算する場合によく用いられる形式です。
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

ワイドデータとロングデータ
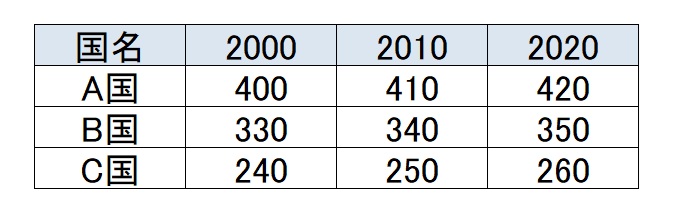
ワイドデータは列に変数や属性、行に観測単位を表したものです。下の表は、各行が国、各列が時間、セルの中が値(人口、GDPなど)を表しています。
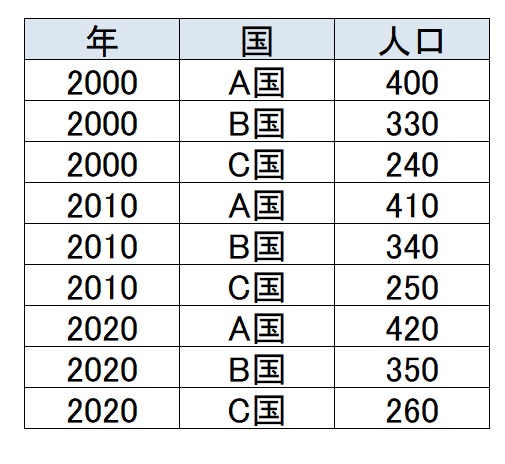
ロングデータは、一つの行が一つの観測値を表すデータで、縦長になります。一つの行に年や属性などをそれぞれ決める値が必要になります。下の表の場合は、まず年のデータがあり、国別に人口のデータがあるというものです。
ロングデータへの変換
ワイドデータをロングデータにするには、もともとある列に加えて、属性などカラム名が表していたデータを列に変換する必要があります。ワイドデータでは2000、2010、2020と列名として並んでいるデータを各行に割り当てることになります。
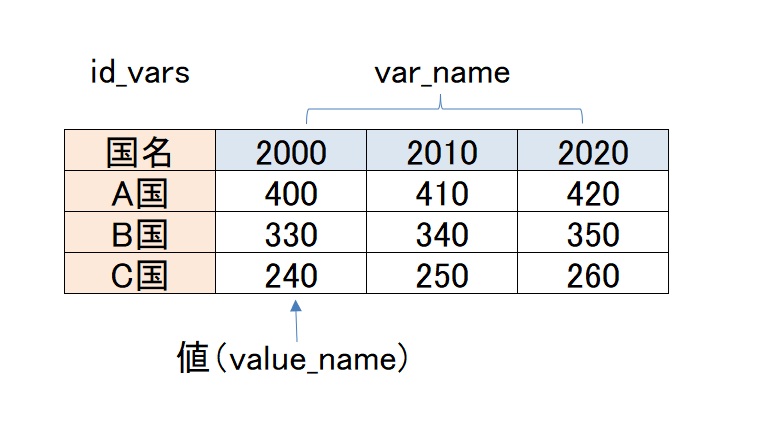
この操作をするのがmeltという関数です。id_vars,var_name,value_nameの3つを指定します。列名がid_vars,カラム名がvar_nameに対応します。
melt(df,id_vars=… ,var_name=… ,value_name=… )id_varsには列名を指定する必要があります。データフレームのインデックスをid_varsとして使用したい場合は、reset_index()メソッドを使用してインデックスを列に変換する必要があります。また、変数の集まりであるリストもid_varsとして指定することもできます。
実際にワイドデータをロングデータにしてみましょう。ワイドデータのカラム名のうち”国名”をid_varsとします。var_nameは、列名として並んでいるもので、2000、2010、2020なので年とします。
df1 = pd.DataFrame({
"国名": ["A国", "B国","C国"],
"2000": [400, 330,240],
"2010": [410, 340,250],
"2020": [420, 350,260]
}) #ワイドデータの作成
df2=pd.melt(df1, id_vars='国名', var_name='年', value_name='人口')
print(df2)出力結果は以下です。
国名 年 人口
0 A国 2000 400
1 B国 2000 330
2 C国 2000 240
3 A国 2010 410
4 B国 2010 340
5 C国 2010 250
6 A国 2020 420
7 B国 2020 350
8 C国 2020 260カラム名はどれでもid_varsにできます。その意味では‘2000’もid_varsにできますが、適切でない表になります。'2000' 列が識別子として扱われ、他の列('国名'、'2010'、'2020')が変数名となり、それぞれに対応するものが値として変換されます。
df2=pd.melt(df1, id_vars='2000', var_name='年', value_name='値')出力は以下の通りです。
2000 年 値
0 400 国名 A国
1 330 国名 B国
2 240 国名 C国
3 400 2010 410
4 330 2010 340
5 240 2010 250
6 400 2020 420
7 330 2020 350
8 240 2020 260行が年、列が国名の場合
ワイドデータにはいろいろなタイプがあります。行が年を表し、列に国が並ぶ場合もあります。
この場合には、年をid_varsにして、var_nameは国名になります。
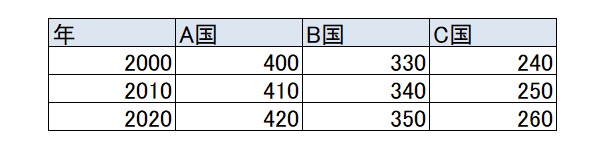
df1 = pd.DataFrame({
"年": ["2000", "2010","2020"],
"A国": [400, 410,420],
"B国": [330, 340,350],
"C国": [240, 250,260]
}) #ワイドデータの作成
df2=pd.melt(df1, id_vars='年', var_name='国名', value_name='人口')
print(df2)出力結果は以下です。
年 国名 人口
0 2000 A国 400
1 2010 A国 410
2 2020 A国 420
3 2000 B国 330
4 2010 B国 340
5 2020 B国 350
6 2000 C国 240
7 2010 C国 250
8 2020 C国 260