numpyの中心的なツールであるndarrayの扱い方について解説します。
arrayの変更や抽出、代入、コピー、数値の作成などの説明です。ndarrayへの数値の代入法などについては、多次元配列(ndarray)の概要を参照してください。
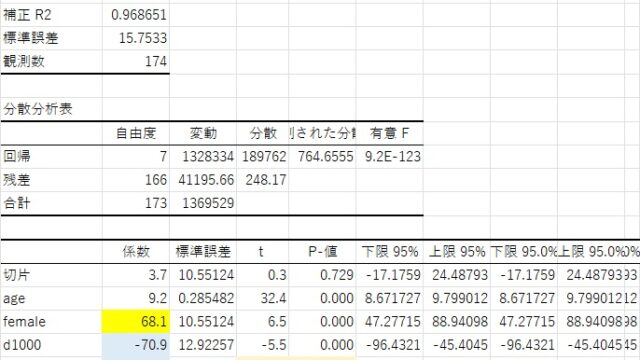
経済統計の使い方では、統計データの入手法から分析法まで解説しています。

変形
変形(reshape)
reshapeメソッドの基本:reshape((タプル))
1次元配列を2次元配列に変換したりすることを変形と呼び、reshapeメソッドを使います。タプルには、次元と要素数をしてします。2次元で2行3列の場合は、(2,3)となります。2行3列の場合は要素は6なので、1次元の場合は要素数が6以外の場合はエラーになります。
a=np.array([1,2,3,4,5,6]) #要素が6
b=a.reshape((2,3))
print(b)出力
[[1 2 3]
[4 5 6]]2行3列の場合は要素は6なので、1次元の場合は要素数が6以外の場合はエラーになります。
a=np.array([1,2,3,4,5,6,7]) #要素が7
b=a.reshape((2,3))
print(b)ValueError: cannot reshape array of size 7 into shape (2,3)1次元化(ravel)
1次元化する場合はravelの場合は参照と同じで、もとのarrayaを変更すると新たに作ったarraybも変更されます。
a=np.array([[1,2,3],[4,5,6]])
b=a.ravel()
print(b)
a[1,1]=0
print(a)
print(b)出力
[1 2 3 4 5 6] <-最初のprint(b)
[[1 2 3] <-変更後のa
[4 0 6]]
[1 2 3 4 0 6] <-連動してbも変わる1次元化(flatten)
同じく1次元化する場合ですが、こちらの場合はコピーと同じで、もとのarrayaを変更しても新たに作ったarraybは変更されません。
a=np.array([[1,2,3],[4,5,6]])
b=a.flatten()
print(b)
a[1,1]=0
print(a)
print(b)出力
[1 2 3 4 5 6] <-最初のprint(b)
[[1 2 3] <-変更後のa
[4 0 6]]
[1 2 3 4 5 6] <-bは変更されないインデックス
インデックスの基本式: ndarray[リスト]
arrayの要素をインデックスで表すことができます。インデックスは各要素にゼロから順番に番号を振ったものです。
1次元arrayのインデックス
arrayが[1,2,3]だとすると、インデックスは[0,1,2]です。インデックス0が1,インデックス1が2,インデックス2が3です。arrayをaとすると、a[1]=2となります。
a=array([1,2,3])
print(a[1])出力
22次元arrayのインデックス
2次元arrayの場合も、行方向、列方向にゼロからインデックスが振られます。2次元のインデックスを作成すると値を指定できます。
a=np.array([[1,2,3],[4,5,6]])
print(a[1,1])出力
52次元arrayに1次元のインデックスを使うと、a[1] 最初の行を選ぶことになります。
a=np.array([[1,2,3],[4,5,6]])
print(a[1])出力
[4 5 6]3次元arrayのインデックス
3次元の場合、3次元のインデックスなら値を2次元のインデックスなら行を1次元のインデックスなら層を指すことになります。
2行3列で2層の3次元配列は以下のようになります。インデックスは層(深さ)、行、列の順に指定します。
インデックスはゼロから振るので、a[0,1,1]は、1層目の2行2列目なので、5になります。
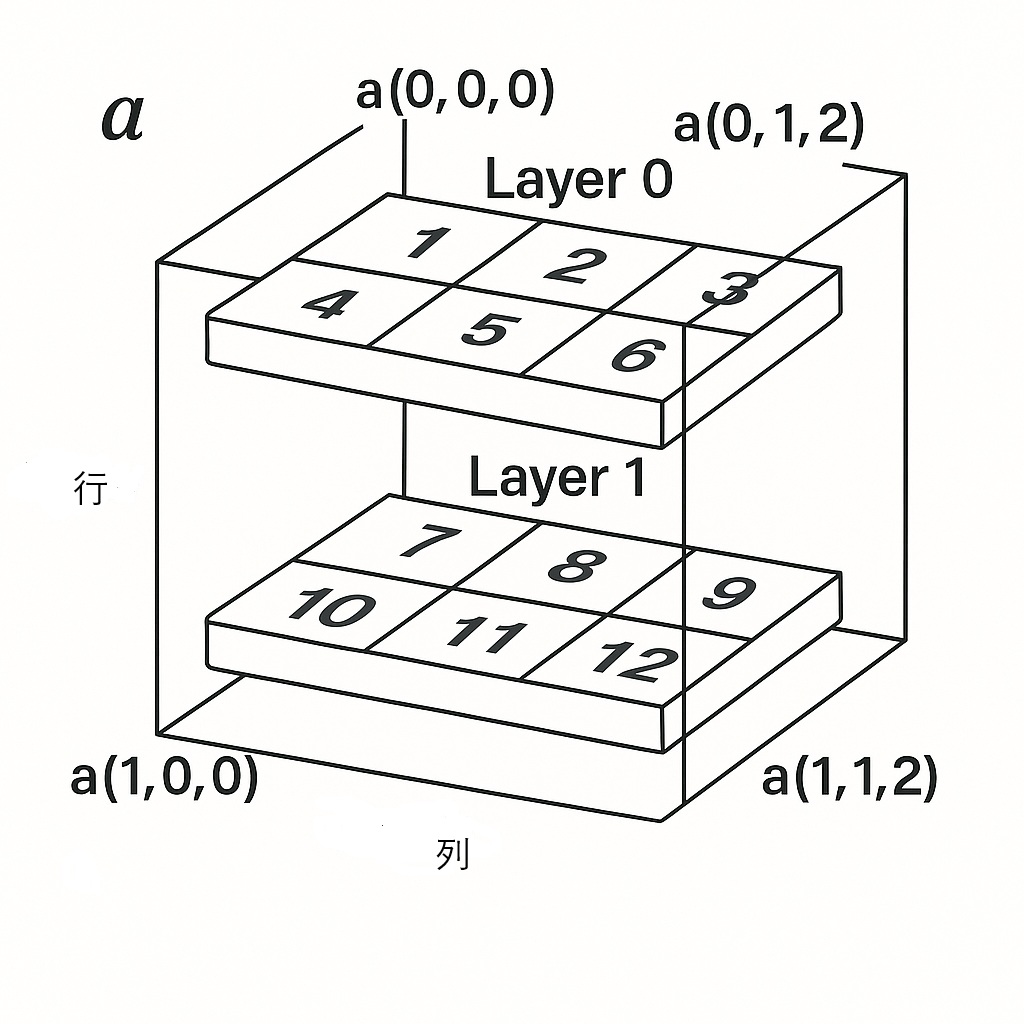
a=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a[0,1,1])出力
52次元のインデックスを指定すると、層、行、列のうち最初の2つである層と行を指定したことになります。a[0,1]の場合は1層目の2行目で、[4,5,6]になります。
a=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a[0,1])
出力
[4 5 6]3次元のインデックスを指定すると、層、行、列のうち最初の層を指定したことになります。
a[0]の場合は1層目なので、[[1 2 3][4 5 6]]を指定したことになります。
a=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a[0])出力
[[1 2 3]
[4 5 6]]スライス記法
スライス記法がarrayにも使えます。スライス記法は、:によって3つの部分に分けられます。a[開始位置:終了位置:間隔]です。a[:]のようにコロンが一つの場合が多いですが、2番目のコロンを省略しているためで、省略すると間隔は1になります。
| 記法 | 意味 | 出力例 |
|---|---|---|
| a[:] | 全要素 | [0 1 2 3 4 5 6] |
| a[::] | 全要素(step省略なし) | [0 1 2 3 4 5 6] |
| a[0:3] | 0番目から2番目まで | [0 1 2] |
| a[2:] | 2番目から最後まで | [2 3 4 5 6] |
| a[:4] | 先頭から3番目まで | [0 1 2 3] |
| a[::2] | ステップ2で取得(偶数番目) | [0 2 4 6] |
| a[1::2] | 1番目からステップ2(奇数番目) | [1 3 5] |
| a[::-1] | 逆順(後ろから) | [6 5 4 3 2 1 0] |
| a[-3:] | 最後から3つ | [4 5 6] |
| a[:-2] | 最後から2つを除いた全要素 | [0 1 2 3 4] |
| a[-4:-1] | 最後から4番目〜2番目(-1は含まない) | [3 4 5] |
データの代入
データの代入:インデックス:ndarray[リスト])=値
データを代入する場合は、インデックスで要素を指定し、その場所に新しい値を代入します。
参照とコピー
同じndarrayを作る場合、参照とコピーの2種類があります。
- 参照の場合は元のndarrayを変更すると新しいndarrayの値も変わる
- コピーの場合は、元のndarrayを変更してもコピーしたndarrayの値は変わらない
aが元データでbが新たなデータとすると、参照の場合はb=aとし、コピーの場合はb=a.copy()メソッドを使います。
参照の場合は数値が連動
ndarrayであるaに対し、参照の形でbを作り、aの1つ目の要素を4に変えた場合です。bも連動して4に変わっていることがわかります。
a=np.array([3,4,5])
b=a
a[0]=4 #参照
print(a)
print(b)出力
[4 4 5]
[4 4 5]コピーの場合は数値は連動しない
ndarrayであるaをコピーしてbを作った場合です。aの1つ目の要素を4に変えても、bの要素は変わりません。
a=np.array([3,4,5])
b=a.copy() #コピー
a[0]=4
print(a)
print(b)出力
[4 4 5]
[3 4 5]数列を作る
数列の基本:np.arange(開始値、最終値の一つ後、間隔)
引数1:終了値+1
引数を1つだけ指定した場合は、最後の数値の一つ後を指定したことになります。開始値はゼロが自動的に設定されます。
a=np.arrange(10)
print(a)出力
[0 1 2 3 4 5 6 7 8 9]引数2:開始値と終了値+1
引数を2つ指定した場合は、最初の数値、最後の数値の一つ後を指定したことになり、間隔は1となります。
a=np.arange(1,10)
print(a)出力
[1 2 3 4 5 6 7 8 9]引数3:開始値、終了値+1、間隔
引数を3つ指定した場合は、最初の数値、最後の数値の一つ後、間隔を指定したことになります。
a=np.arange(1,10,2)
print(a)出力
[1 3 5 7 9]均等割り
均等割り:np.linspace(開始値、終了値、要素数)
開始値と終了値を指定して、その中の要素数を決める場合です。1から9までの数字で要素数を5とすると、1,3,5,7,9のarrayとなります。
a=np.linspace(1,9,5)
print(a)出力
[1. 3. 5. 7. 9.]決まった値をいれる
決まった値を入れる場合をいくつか紹介します。
ゼロ
ゼロでarrayを作る:a=np.zeros(タプル)
すべての要素にゼロを入れる場合です。タプルでarrayの次元数、要素数を決めます。2次元で2行3列の場合は(2,3)です。
a=np.zeros((2,3))
print(a)出力
[[0. 0. 0.]
[0. 0. 0.]]1
1でarrayを作る:a=np.ones(タプル)
すべての要素に1を入れる場合です。タプルでarrayの次元数、要素数を決めます。2次元で2行3列の場合は(2,3)です。
a=np.ones((2,3))
print(a)出力
[[1. 1. 1.]
[1. 1. 1.]]単位行列
単位行列を作る:a=eye(3)
単位行列を作成する場合です。対角要素が1、ほかがゼロの行列です。正方行列の必要があるので、指定するのは行数=列数の一つです。
a=np.eye(3)
print(a)出力
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]指定値で埋める
指定値で埋める:a=np.full((3,4),3)
指定値で埋める場合です。タプルで次元の数と要素の数を決め、その後に数値を指定します。
a=np.full((3,4),3)
print(a)出力
[[3 3 3 3]
[3 3 3 3]
[3 3 3 3]]
nanを埋める
nanで埋める:a=np.full((3,4),np.nan)
欠損値の穴埋めをする場合はnanを埋めておきます。nanはNot a Numberの略で、数値ではないということです。
a=np.full((3,4),np.nan)
print(a)出力
[[nan nan nan nan]
[nan nan nan nan]
[nan nan nan nan]]乱数
乱数を入力するには、まず乱数ジェネレーターを起動して、その後は、rng.random()関数で乱数を発生させます。以下で乱数を起動させます。
rng = np.random.default_rng()
乱数発生の基本は以下の式です。同じ乱数を使いたい場合は()内に123などの数値を入れます。数字の同じ場合は同じ乱数が発生されます。
乱数の基本式:rng.random(タプル)
タプルでは、次元を決め、要素数を指定します。2次元配列で2行3列なら、(2,3)です。乱数は0以上1未満の数値がランダムに入ります。
rng = np.random.default_rng()
a=rng.random((2,3))
print(a)出力
[[0.88815588 0.12439094 0.87177215]
[0.96483097 0.86617194 0.99765329]]整数の乱数
整数だけで乱数を発生させることもできます。最初の数と最後の数を指定します。sizeのタプルで次元を決め、要素数を決めます。省略すると一次元arrayになります。
整数の乱数:rng.integers(最初の数,最後の数の一つ後,size=(タプル))
rng = np.random.default_rng()
a=rng.integers(0,10,size=(10))
print(a)出力
[4 1 8 0 6 7 8 7 9 5]正規分布の乱数
正規分布の乱数を発生させる場合は、平均と標準偏差を指定します。平均0、標準偏差1を指定すると標準正規分布になります。
正規分布の乱数:rng.normal( 平均,標準偏差,size=(タプル))
sizeを省くと1次元配列になります。
rng = np.random.default_rng()
a=rng.normal(0,10,size=(10))
print(a)出力
[ 2.87273918 7.98556469 9.63666071 -5.52469409 9.59161518
-10.63625467 -4.45821382 2.66016268 -6.52019161 -7.83909633]arrayの結合
arrayの連結
arrayの連結:c=np.concatenate([a,b],axis=数字)
2つのarrayを連結します。連結する2つのarrayをリストで表します。連結する方向としては、行方向に連結する場合と列方向に連結する場合が考えられます。行方向に連結する場合はaxis=0,列方向に連結する場合はaxis=1です。axis=0は省略することができます。
a=np.array([[1,2,3],[1,2,3]])
b=np.array([[4,5,6],[4,5,6]])
c=np.concatenate([a,b],axis=0)
print(c)出力
[[1 2 3]
[1 2 3]
[4 5 6]
[4 5 6]]次はaxis=1とした場合です。
a=np.array([[1,2,3],[1,2,3]])
b=np.array([[4,5,6],[4,5,6]])
c=np.concatenate([a,b],axis=1)
print(c)出力
[[1 2 3 4 5 6]
[1 2 3 4 5 6]]行方向に連結する場合はnp.vstack関数、列方向に連結するばあいはnp.hstack関数をつかうこともできます。stackは積み重ねる、vは垂直(vertical)、hは水平(horizontal)を表します。
a=np.array([[1,2,3],[1,2,3]])
b=np.array([[4,5,6],[4,5,6]])
c=np.vstack([a,b])
d=np.hstack([a,b])
print(c)
print(d)出力
[[1 2 3] <-vstack関数の結果
[1 2 3]
[4 5 6]
[4 5 6]]
[[1 2 3 4 5 6] <-hstack関数の結果
[1 2 3 4 5 6]]arrayの分割
arrayの行方向への分割:b,c=np.vsplit(a,[2])
arrayの列方向への分割:b,c=np.hsplit(a,[2])
2次元arrayを分割する場合、行方向への分割はnp.vsplit関数、列方向の分割はnp.hsplit関数を使います。[2]は1番目のarrayの行数、列数を表します。
a=np.array([[1,2,3],[4,5,6],[7,8,9]])
b,c=np.vsplit(a,[2])
print(b)
print(c)出力
[[1 2 3] ->print(b)の結果
[4 5 6]]
[[7 8 9]] ->print(c)の結果列方向への分割は以下の通りです。
a=np.array([[1,2,3],[4,5,6],[7,8,9]])
b,c=np.hsplit(a,[2])
print(b)
print(c)出力
[[1 2] ->print(b)の結果
[4 5]
[7 8]]
[[3] ->print(c)の結果
[6]
[9]]arrayの転置
arrayの転置:a.T
2次元array(行列)の行と列とを入れ替える場合です。Tというメソッドを使います。
a=np.array([[1,2,3],[4,5,6]])
b=a.T
print(a)
print(b)出力
[[1 2 3] <-print(a)の結果
[4 5 6]]
[[1 4] <-print(b)の結果
[2 5]
[3 6]]