

pythonでランダムフォレストの予測をしてみます。skleranのensembleというモジュールの中のRandomForestRegressorというクラスを使い、以下の式で計算できます。
RandomForestRegressor(木の数)
このモデルの計算結果はfitメソッドを使うと保存されます。この結果を使って、結果の確認、係数の出力や予測などができます。
経済統計の使い方では、経済統計の入手法から分析法まで解説しています。

データは、以下のデータを使います。景気動向指数のデータです。
import pandas as pd
df=pd.read_csv("CI.csv")
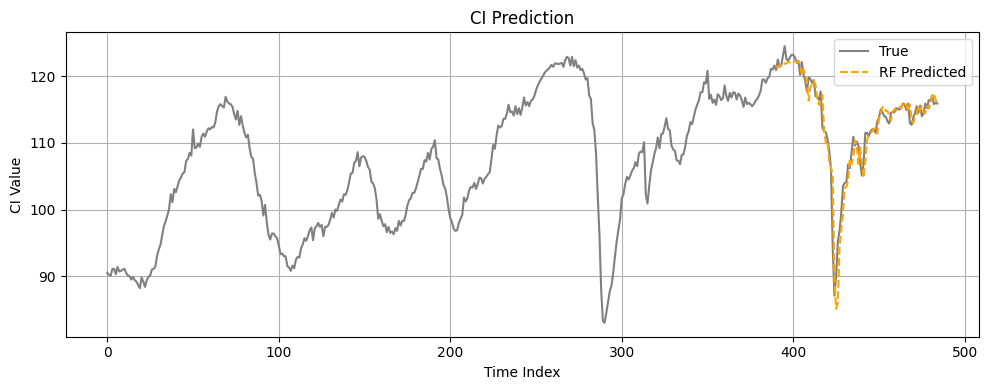
df.head()景気動向指数のデータです。灰色の線が実績値、オレンジが検証期間の推定値となっています。
ランダムフォレスト
ランダムフォレストは、サンプルを変えて決定木を何度もやって、それらの平均をとることで予測値を計算するものです。決定木は、分類に使うことも多いですが、今回は連続した数値を予測する回帰として使っています。
決定木だけでも複雑さの度合いなど、さまざまなハイパーパラメーターがあり、ランダムフォレストにもいくつかの選択肢がありますが、最も実行するには、木の数だけを決めることです。このままだとランダムに結果が変わるので、結果をいつも同じにしたいときは、同じ乱数を使うようにするため、randamstate=0を追加します。
statsmodelsの回帰分析などではモデルを作成した段階でデータを指定するものが多いですが、機械学習ではfitの段階でデータを指定します。
rf=RandomForestRegressor(木の数)
このモデルを使って係数を推定する場合は、fitメソッドを使います。ここで、説明変数と目的変数を設定します。説明変数(X)は複数の系列、目的変数(y)は一つの系列です。
rf.fit(説明変数,目的変数)
この結果を使って目的変数の推定や予測を行います。rfというモデルに対して、predictというメソッドを使い、変数rf_predが出力されます。
rf_pred = rf.predict(入力データ)
| fit(入力データ、目標値) | 係数の推定 |
| predict(入力データ) | 目的変数の推定、予測 |
学習期間と検証期間
機械学習では、学習期間の説明変数、目的変数で学習して、検証期間の説明変数を使って、目的変数を予測するのが一般的です。
学習データをサンプル数の80%とすると、サンプル数×0.8で学習データ数(train_size)が求められます。
今回の予測では自分自身の過去の値を説明変数として、現在の値を予測するというモデルになります。
目的変数y_rf_allの初期はインデックスではn_timeになります。最初のいくつかのデータは説明変数として使うためです。
一方、説明変数は少し複雑になります。X_rf_allを入力値でデータとします。y_rf_allのn_time期前から1期前までのデータを毎期作る必要があります(スライディングウインドウと呼びます)。
X_rf_all = np.array([ci[i:i+n_time] for i in range(n_sample)])
これは、ゼロからn_sample-1までについて、ci[i:i+n_time]を取り出して、リストにしていることを表します。最初はci[0:0+n_time]なので、インデックスが0からn_time-1までのデータとなります。これが目的変数の初期に対応する説明変数です。それ以降は以下のようにデータを作ることになります。
ci[0:n_time]
ci[1:n_time+1]
:
ci[n_sample-1:n_sample-1+n_time]
時点を一つずつずらしながらデータを作成し、それがリストになっています。このリストをリストの形つまり、np.array([[],[]])という形にして2次元配列を作ります。
| インデックス | 目的変数 | 説明変数1 | … | 説明変数n_time |
| 0 | $y-{t-n_time}$ | |||
| : | : | |||
| n_time | $y_t$ | $y_{t-1}$ (インデックスはn_time-1) | … | $y_{t-n_time}$ (インデックスは0) |
学習期間と検証期間の初期と終期は
学習期間:初期0、終期 train_size
検証期間:初期traine_size、終期 最後まで
プログラム
プログラムはグーグルドライブに上げたファイルから読み込む場合です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from google.colab import drive
# Google Driveから読み込み
drive.mount('/content/drive', force_remount=True)
ci_df = pd.read_csv('/content/drive/MyDrive/MGDP/CI.csv')
ci = ci_df['ci'].values.astype(np.float32)
# サンプル数など
n_time = 12
n_sample = len(ci) - n_time
train_size = int(n_sample * 0.8)
# ランダムフォレスト予測
X_rf_all = np.array([ci[i:i+n_time] for i in range(n_sample)])
y_rf_all = ci[n_time:]
X_rf_train = X_rf_all[:train_size]
y_rf_train = y_rf_all[:train_size]
X_rf_val = X_rf_all[train_size:]
Y_rf_val=y_rf_all[train_size:]
rf = RandomForestRegressor(n_estimators=100, random_state=0)
rf.fit(X_rf_train, y_rf_train)
rf_pred = rf.predict(X_rf_val)
# 評価関数を定義
def evaluate_model(name, y_true, y_pred):
print(f"\n{name}")
print("RMSE:", np.sqrt(mean_squared_error(y_true, y_pred)))
print("MAE :", mean_absolute_error(y_true, y_pred))
print("R² :", r2_score(y_true, y_pred))
# 評価関数を表示
evaluate_model("Random Forest", Y_rf_val, rf_pred)
# 実績値(全期間)と予測値(検証期間)を同時表示
plt.figure(figsize=(10, 4))
plt.plot(ci, label="True", color='gray')
plt.plot(np.arange(train_size + n_time, train_size + n_time + len(rf_pred)),
rf_pred, label="RF Predicted", linestyle='--', color='orange')
plt.legend()
plt.title("CI Prediction")
plt.xlabel("Time Index")
plt.ylabel("CI Value")
plt.grid(True)
plt.tight_layout()
plt.show()












